One of the key things we’ve learned researching the vulnerability landscape is that there is a strong relationship between publicly available exploit code and actually seeing an exploit used in the wild. We noticed way back in 2018 that vulnerabilities with published exploit code are as much as 7 times as likely to be exploited in the wild. We ‘exploited’ (heh) this fact when developing EPSS version 1. What also seems to matter is how that code is published. If it’s ‘weaponized’ (think metasploit), the odds of a vulnerability being exploited in the wild really balloon from about 3.7% to 37.1%.
It seems rather logical that anyone in and/or around vulnerability management may want to keep an ear to the ground for exploits being published to aid in prioritization. One obvious place is Exploit DB, and that was certainly a prominent source in early research and is heavily used in academic research. Another source for weaponized exploits are the frameworks such as metasploit. The frameworks generally have more refined exploits and end up with less overall exploits than something like Exploit DB. However, we’ve noticed a slow shift in how exploits are being published. There is a new player for exploit publishing: GitHub. 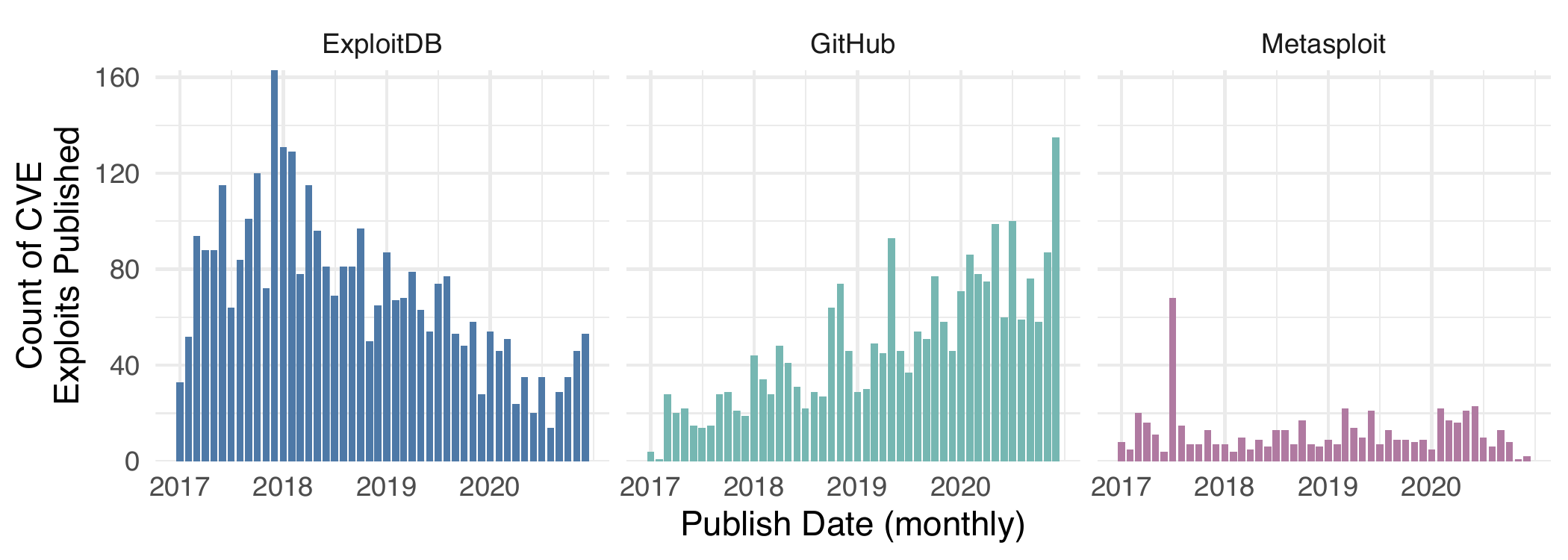 Compared to other popular venues, since 2017 (incidentally, that’s when CVE CNA process started), ExploitDB has seen a decline, metasploit has been constant, but the number of exploits on GitHub has steadily increased. “But wait!” you might say, “How can we tell if a GitHub repository has exploit code?”, and to that we say: “I’m glad you asked”.
Compared to other popular venues, since 2017 (incidentally, that’s when CVE CNA process started), ExploitDB has seen a decline, metasploit has been constant, but the number of exploits on GitHub has steadily increased. “But wait!” you might say, “How can we tell if a GitHub repository has exploit code?”, and to that we say: “I’m glad you asked”.
How are exploits found on GitHub?
This is a tricky (read “fun”) question to answer, because anyone can create a github repository and there are no rules, limitations or standards for what a working exploit will look like once published to github. So we have to separate the exploit wheat from the chaff so-to-say, and this is a data science/machine learning problem that is right up Cyentia’s alley.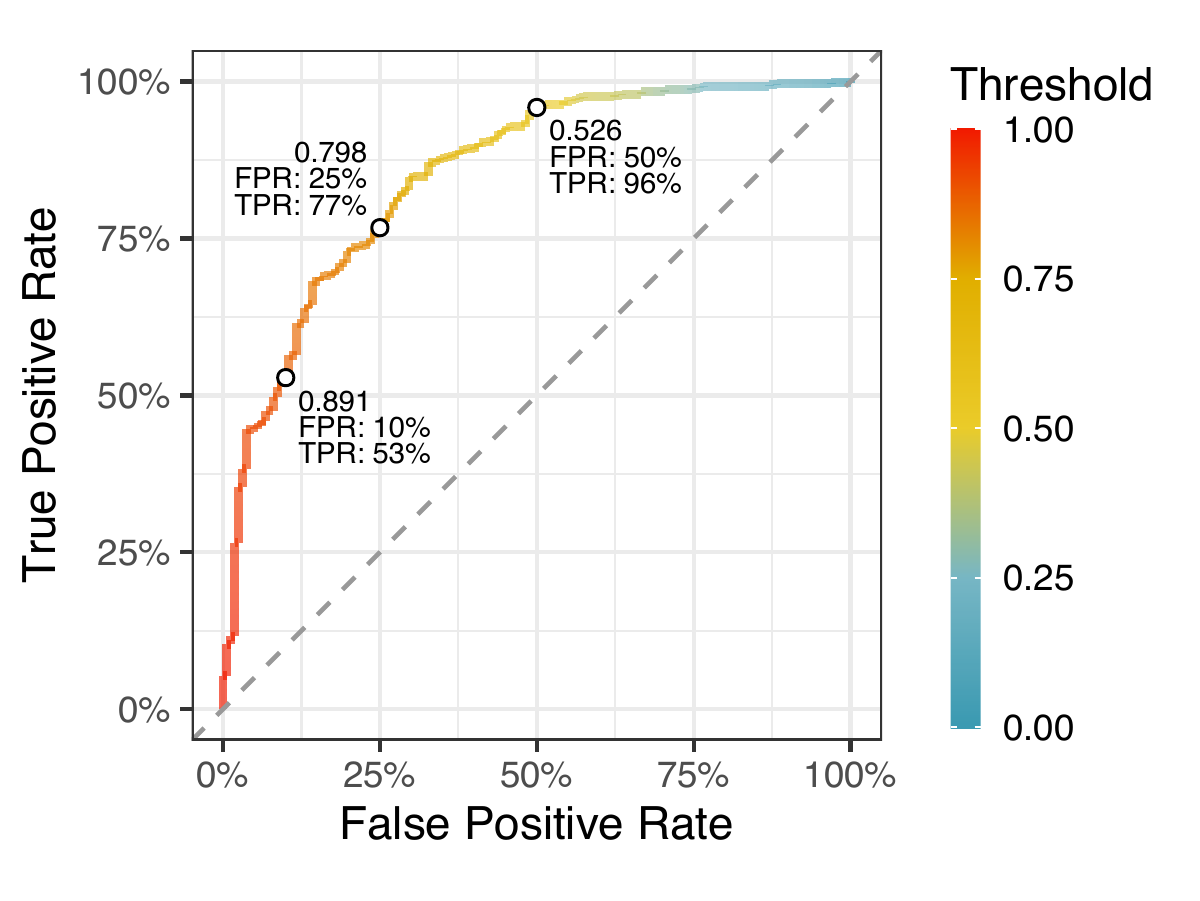
We won’t get into the minutiae of that data and algorithms here; we’ll leave that pile of data engineering, feature engineering, and model building for later discussions. But we do want to show off how well our initial classifier works. The figure to the right shows a “receiver operator characteristic” curve (or “ROC curve”) which shows the True Positive Rate against the False Positive Rate . The True Positive Rate measures the proportion of repositories the model correctly classifies as containing an exploit and the False Positive Rate measures the proportion of repositories the model incorrectly classifies as having an exploit when it doesn’t. Now the model itself doesn’t actually give out a binary “exploit or not” answer. Instead, the model outputs a value between zero and one, and we can pick a threshold to tailor the classification to our tolerances — that’s what the ROC curve is showing us. If you notice in the plot we identified three points on the curve at False Positive Rates of 10%, 25% and 50%. If we wanted to keep the false positives to a minimum (10%) we would set the threshold at 0.891 (any repository scored at or above 0.891 would be classified as containing an exploit). At that threshold we would have a corresponding True Positive Rate of 53%. But at the other end, if we are okay with a False Positive Rate of 50%, we set the threshold at 0.526 and we’d have a True Positive Rate of 96%. The key here is understanding that the model isn’t perfect and we have to make some tradeoffs. Undoubtedly this model will get better over time as we get more manually validated repositories.
Wrapping up
We know from our research that vulnerabilities with published exploits are more likely to be exploited in the wild. We can also state that the publishing of exploits is largely ad hoc, unstructured and the publishing appears to be shifting slowly away from ExploitDB and towards publishing exploits on GitHub. While our model isn’t perfect, we can use it to significantly cut down on the manual effort of inspecting every repository but at the cost of some misclassified repositories. If you are working in or around vulnerabilities and think that this type of information would be helpful, check out our Exploit Intelligence Service and reach out with any questions.